

NDA
DataFlow / Новые пресеты для операций (job's)
Eastwind • B2B • 2023-2025
DataFlow превращает сложную работу с большими данными
в понятный и гибкий процесс, от загрузки до машинного обучения.
С ней аналитики работают с Hadoop так же свободно,
как с локальными инструментами
Роль: Product Designer
Команда: PM, Tech Lead, Backend, Frontend, QA, DevOps
Контекст
DataFlow — B2B-платформа для работы с большими данными на базе Hadoop. Аналитики, дата-сайентисты и инженеры используют её чтобы строить пайплайны обработки данных: загружать, трансформировать, обучать модели и экспортировать результаты.
Каждый шаг пайплайна — это отдельная операция (job), у которой есть десятки настроек. Одна из них — пресет: конфигурация CPU и RAM, которую получает джоб
при запуске.
Проблема — глазами пользователя
Аналитик запускает джоб. Через некоторое время, ошибка. Он открывает логи, перечитывает код, проверяет входные данные. Всё выглядит правильно. Он запускает снова. Снова ошибка. Через несколько часов поисков кто-то из коллег замечает: кластер полностью зарезервирован под фоновые задачи, ресурсов просто
не хватает.
Именно так описывали свой опыт пользователи на интервью. Проблема была не в коде, она была невидимой. И это делало её особенно болезненной: человек сомневался
в себе, тратил время впустую и в итоге шёл в техподдержку.
Как я нашёл корень проблемы
Первый сигнал пришёл из техподдержки: пользователи регулярно жаловались
на падающие джобы, не понимая причины.
Я провёл серию интервью и выяснил паттерн: почти все создавали джобы с дефолтным пресетом для всех типов операций одинаковым.
Никто не думал о ресурсах, потому что интерфейс не давал никакого сигнала что
это важно. Дефолт воспринимался как «норма».
Корень проблемы: один пресет на все случаи жизни — это не нейтральный выбор,
это скрытая нагрузка на кластер.

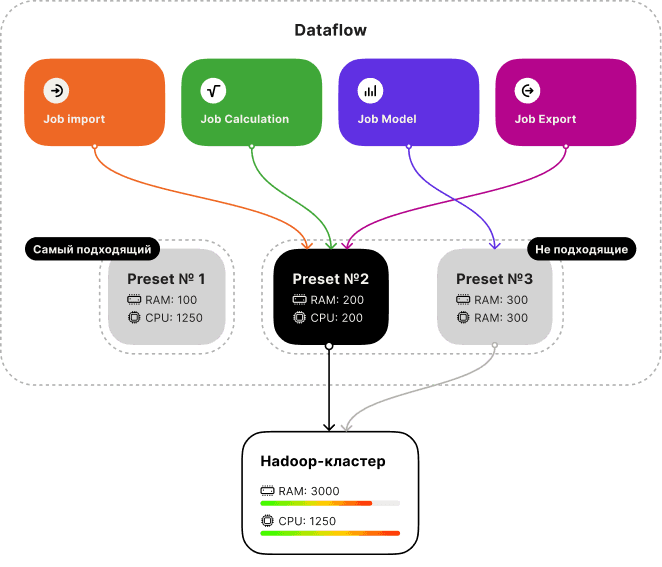
Исследование: что нужно пресетам
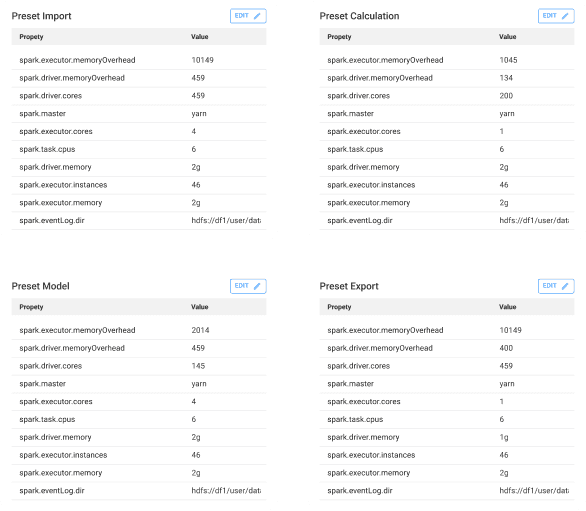
Я изучил принципы работы кластера и совместно с аналитиком собрал конфигурации для четырёх типов операций: Import, Calculation, Model, Export. Каждый тип потребляет ресурсы по-своему.
В ходе интервью выяснилось неожиданное: даже джобы одного типа потребляют разное количество ресурсов в зависимости от объёма данных и сложности задачи. Жёсткие конфигурации не решали проблему. Нужна была гибкость.
Решение предложили сами пользователи-аналитики: размерность S / M / L для каждого типа операции. Привычная логика, которая не требует обучени
Первое решение и неожиданный результат
Мы запустили систему пресетов. Новые джобы стали создаваться с осознанным выбором конфигурации — это сразу дало эффект. Но я начал собирать статистику
по использованию фичи и обнаружил проблему: старые джобы, которые «и так работали», никто не трогал. Пользователи не хотели останавливать работающие процессы ради смены настроек.
Фича существовала, но не меняла ситуацию для большей части кластера.
Это был важный сигнал.

Второе решение: Автоматизация
На основе этих данных сформулировали гипотезу: если убрать необходимость ручного действия — adoption вырастет.
Реализовали два механизма:
Автомиграция для легаси: джобы, которые остановились (с ошибкой или штатно), автоматически получали оптимальный пресет под свой тип
Умный выбор при создании: новый джоб сразу предлагал три подходящих пресета вместо одного дефолтного
Это убрало барьер и сформировало правильное поведением по умолчанию.


Техническая основа автомиграции — присвоение уникального ID каждому типу операции. Во время очередного релиза система автоматически сопоставляла существующие джобы с соответствующими ID и применяла нужный пресет.
Это позволило провести миграцию без участия пользователей
и без остановки работающих процессов.

Результаты
Метрика — среднее время выполнения джоба до и после применения оптимального пресета. Данные собирались через мониторинг кластера за 30 дней до релиза и 30 дней после.
Старые джобы после автомиграции: −63% времени выполнения
Новые джобы с осознанным выбором пресета: −88% времени выполнения
Дополнительно: снизилось количество обращений
в техподдержку по теме падающих джобов, сформировались новые гипотезы для бэклога, появились артефакты описывающие распределение ресурсов в кластере — их использовали как базу знаний внутри команды.
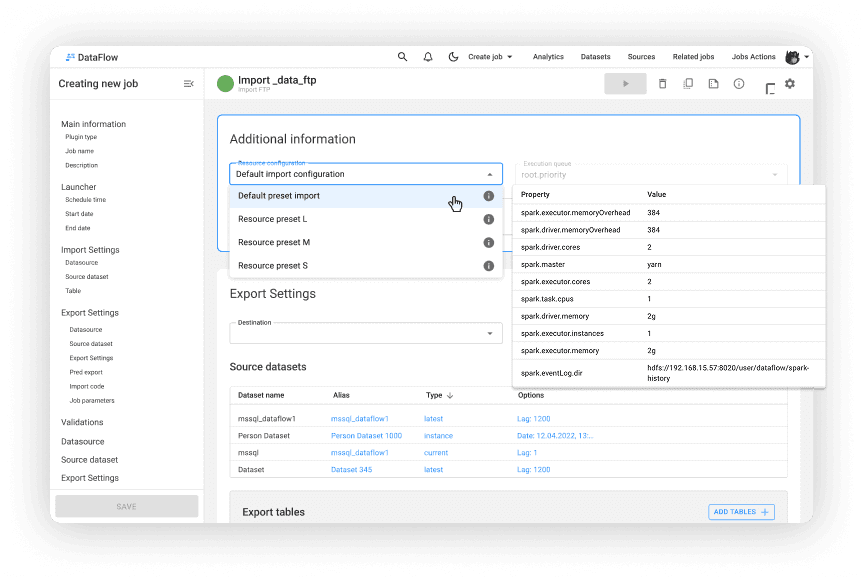
Пресеты в шаблоне операции (job)
Выбор типа конфигурации и превью настроек
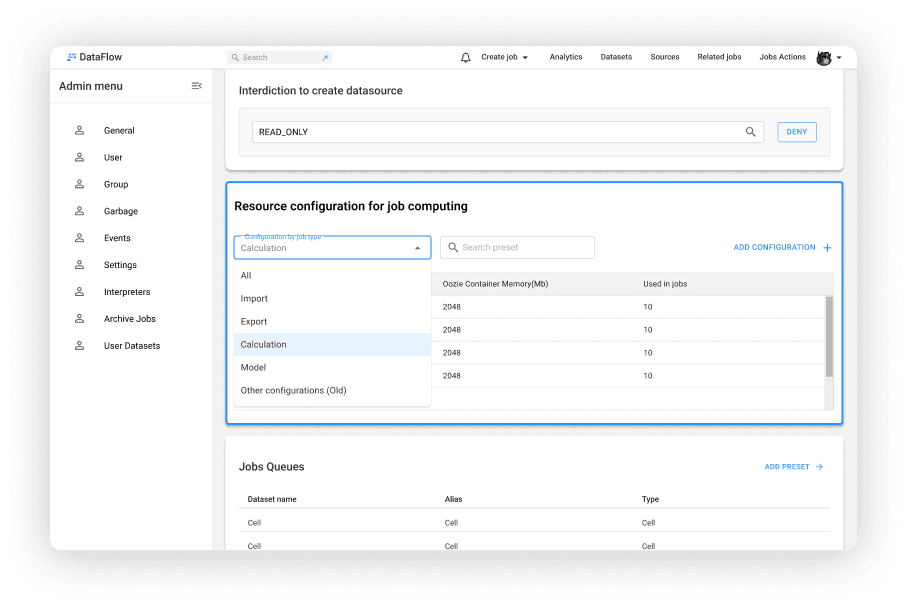
Пресеты в Admin menu
Таблица конфигураций для Calculation
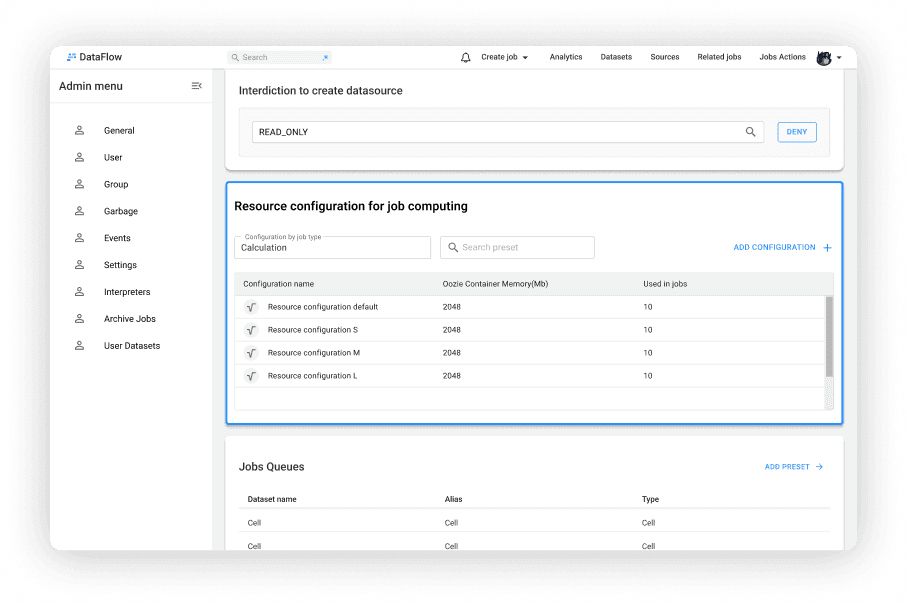
Фильтр пресетов в Admin menu
Выбор типа конфигурации
Polyphone
Следующий